




I. Introduction▲
Les structures arborescentes font partie des fondations de l’informatique. Elles permettent de représenter naturellement des données hiérarchiques, que l’on retrouve dans de nombreux domaines : systèmes de fichiers, interfaces graphiques, organisation de documents ou encore intelligence artificielle.
Un système de fichiers, par exemple, est un arbre :
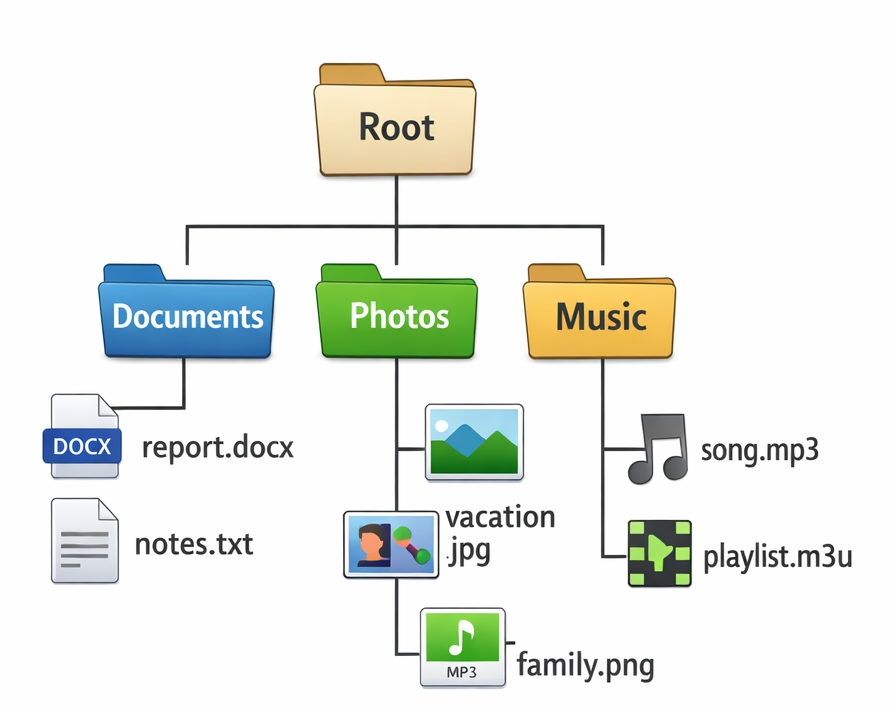
Chaque dossier peut contenir des sous-dossiers et des fichiers, qui eux-mêmes peuvent contenir d’autres éléments. Cette organisation hiérarchique est intuitive et reflète la manière dont nous structurons naturellement l’information.
Un arbre est une structure où chaque élément peut contenir d’autres éléments similaires.
Cette propriété nous amène directement à un concept fondamental : la récursivité, qui consiste à résoudre un problème en le décomposant en sous-problèmes de même nature.
Dans cet article, tous les exemples seront implémentés en Python afin de privilégier la clarté et la lisibilité. Les concepts présentés restent cependant applicables à la plupart des langages de programmation.
Nous allons progressivement découvrir comment représenter, parcourir et stocker des structures arborescentes, tout en comprenant le rôle central de la récursivité.
II. Arbres et récursivité : un lien naturel▲
Un nœud d’arbre peut contenir d’autres nœuds, appelés enfants.
Cette organisation hiérarchique se répète à chaque niveau : chaque enfant peut à son tour posséder ses propres enfants.
Un arbre est une structure récursive : chaque nœud peut être vu comme la racine d’un sous-arbre.
Cette propriété n’est pas seulement théorique : elle correspond exactement à la manière dont on manipule ces structures en programmation.
En Python, on peut représenter un nœud de manière très simple :
class Node:
def __init__(self, value):
self.value = value
self.children = []Chaque nœud possède une valeur et une liste d’enfants. Ces enfants sont eux-mêmes des instances de Node, ce qui permet de construire une structure potentiellement infinie.
Par exemple, on peut créer un arbre manuellement :
a = Node("A")
b = Node("B")
c = Node("C")
d = Node("D")
a.children = [b, c]
b.children = [d]La structure obtenue peut être représentée sous forme textuelle :
A
├── B
│ └── D
└── CIci, A est la racine de l’arbre, avec deux enfants B et C. Le nœud B possède lui-même un enfant D.
On retrouve clairement la hiérarchie : A est la racine, B et C sont ses enfants, et D est un enfant de B.
Cette organisation illustre concrètement la nature récursive de l’arbre : chaque partie de la structure reproduit le même schéma que l’ensemble.
C’est précisément cette propriété qui rend la récursivité si naturelle pour travailler avec les arbres : une fonction peut s’appliquer à un nœud, puis se réappliquer de la même manière à chacun de ses enfants.
Cette apparente simplicité est trompeuse : ce modèle minimaliste suffit à représenter des structures très complexes. On le retrouve partout en informatique, qu’il s’agisse de systèmes de fichiers, d’arbres de décision en intelligence artificielle ou encore d’arbres syntaxiques en compilation.
III. Parcourir un arbre : comprendre la récursivité▲
III-A. Version récursive▲
Cette fonction parcourt l’arbre en profondeur (parcours DFS) :
def parcourir(noeud):
print(noeud.value)
for enfant in noeud.children:
parcourir(enfant)Le principe est simple :
- On traite le nœud courant (affichage de sa valeur)
- On appelle récursivement la fonction sur chacun de ses enfants
Chaque appel applique exactement le même traitement, quelle que soit la profondeur.
Exemple d’arbre :
A
├── B
│ └── D
└── COrdre de parcours :
A
B
D
CLe parcours suit une logique « profondeur d’abord » :
- On visite d’abord le nœud racine (A)
- Puis on descend dans le premier sous-arbre (B)
- On continue jusqu’à atteindre une feuille (D)
- On remonte ensuite pour explorer les autres branches (C)
Ce comportement est directement lié à la récursivité : chaque appel de fonction suspend son exécution le temps de traiter un sous-arbre, puis reprend là où il s’était arrêté.
Ce type de parcours est appelé DFS (Depth-First Search), ou parcours en profondeur.
La simplicité de cette implémentation masque un mécanisme puissant : la pile d’appels gère automatiquement le retour en arrière dans l’arbre.
III-B. Comprendre la pile d’appels▲
Lorsqu’une fonction récursive est appelée, son contexte (variables locales, position dans le code, paramètres) est stocké dans une structure appelée pile d’appels.
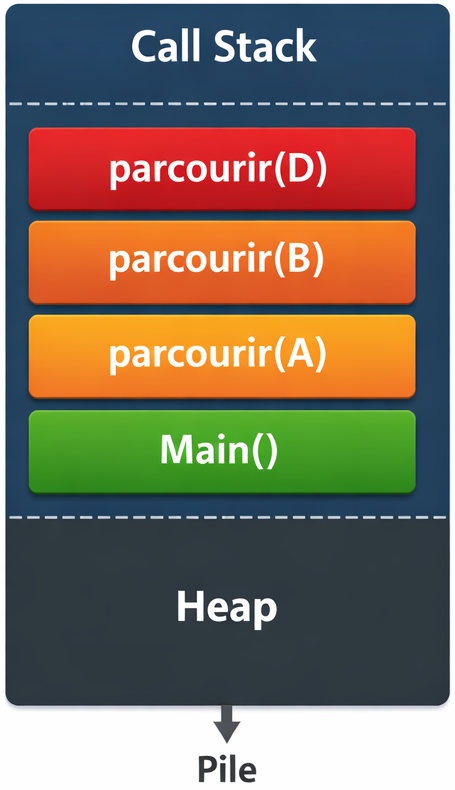
Chaque nouvel appel est empilé au-dessus du précédent. Tant qu’un appel n’est pas terminé, le programme ne peut pas reprendre l’exécution de celui qui l’a invoqué.
Cela signifie que l’on descend dans l’arbre jusqu’à atteindre une feuille, puis que l’on remonte progressivement en dépilant les appels.
Exemple de déroulement pour l’arbre précédent :
parcourir(A)
parcourir(B)
parcourir(D)
parcourir(C)Chaque niveau d’indentation correspond à un appel empilé. Lorsque parcourir(D) se termine, l’exécution reprend dans parcourir(B), puis remonte jusqu’à parcourir(A).
On peut visualiser cela comme une pile d’assiettes : on empile les appels au fur et à mesure, puis on les retire dans l’ordre inverse (dernier entré, premier sorti).
Ce comportement est appelé LIFO (Last In, First Out) et constitue le fondement du fonctionnement de la récursivité.
Une récursivité trop profonde peut provoquer un dépassement de pile (stack overflow), entraînant l’arrêt du programme.
Dans ce cas, il est souvent préférable d’utiliser une version itérative avec une pile explicite, comme nous allons le voir dans la section suivante.
III-C. Version itérative▲
Cette version reproduit le comportement de la récursion, mais sans appel de fonction :
def dfs_iteratif(root):
stack = [root]
while stack:
node = stack.pop()
print(node.value)
stack.extend(reversed(node.children))On utilise une pile explicite pour gérer les nœuds à visiter.
- On commence avec la racine dans la pile
- On dépile un nœud, on le traite
- On empile ses enfants
L’utilisation de reversed() permet de conserver le même ordre de parcours que la version récursive.
Cette approche évite les problèmes de dépassement de pile liés à la récursivité.
Après avoir exploré le parcours en profondeur, voyons maintenant une approche complémentaire : le parcours en largeur.
IV. Parcours en largeur (BFS)▲
Le parcours en largeur (Breadth-First Search, BFS) consiste à explorer un arbre niveau par niveau.
Contrairement au parcours en profondeur (DFS), qui descend dans une branche avant de revenir en arrière, le BFS visite tous les nœuds d’un même niveau avant de passer au suivant.
Pour cela, on utilise une structure de file (FIFO : First In, First Out).
from collections import deque
def bfs(root):
queue = deque([root])
while queue:
node = queue.popleft()
print(node.value)
queue.extend(node.children)Le fonctionnement est le suivant :
- On place la racine dans la file
- On retire le premier élément de la file
- On traite ce nœud (affichage)
- On ajoute ses enfants à la fin de la file
- On répète jusqu’à ce que la file soit vide
Exemple d’arbre :
A
├── B
│ └── D
└── COrdre de parcours en largeur :
A
B
C
DDéroulement de la file :
File initiale : [A]
On traite A → on ajoute B, C
File : [B, C]
On traite B → on ajoute D
File : [C, D]
On traite C → aucun enfant
File : [D]
On traite D → aucun enfant
File : []Le BFS est particulièrement utile pour :
- trouver le plus court chemin dans un graphe non pondéré
- analyser les niveaux d’une structure hiérarchique
- effectuer des parcours par couches (ex : réseaux, IA, jeux)
Le BFS garantit de visiter les nœuds dans l’ordre de leur distance à la racine.
Après avoir vu comment parcourir et manipuler un arbre en mémoire, se pose naturellement la question de sa persistance. Comment conserver une structure arborescente de manière durable, notamment dans une base de données relationnelle ?
V. Stocker un arbre dans une base de données▲
Les structures arborescentes peuvent être stockées dans une base de données relationnelle, même si celles-ci ne sont pas conçues nativement pour représenter des hiérarchies.
Plusieurs modèles existent, chacun avec ses avantages et ses contraintes. Le plus simple est le modèle parent-enfant.
V-A. Modèle parent-enfant▲
Dans ce modèle, chaque nœud contient une référence vers son parent.
CREATE TABLE nodes (
id INTEGER PRIMARY KEY,
value TEXT,
parent_id INTEGER
);La colonne parent_id contient l’identifiant du nœud parent. La racine de l’arbre est représentée par une valeur NULL.
Exemple de données :
id | value | parent_id
----------------------
1 | A | NULL
2 | B | 1
3 | C | 1
4 | D | 2Ces données correspondent à l’arbre suivant :
A
├── B
│ └── D
└── CLe nœud A est la racine (parent_id = NULL). Les nœuds B et C sont ses enfants, et D est un enfant de B.
Cette double représentation permet de faire le lien entre la structure relationnelle (table) et la structure hiérarchique (arbre).
Cette structure est simple à mettre en place et intuitive, mais elle nécessite des requêtes récursives pour reconstruire l’arbre.
Chaque nœud référence son parent, ce qui permet de reconstituer la hiérarchie.
V-B. Insertion récursive▲
Pour insérer un arbre complet en base, on peut utiliser une fonction récursive.
def inserer(noeud, parent_id=None):
cursor.execute(
"INSERT INTO nodes (value, parent_id) VALUES (?, ?)",
(noeud.value, parent_id)
)
node_id = cursor.lastrowid
for enfant in noeud.children:
inserer(enfant, node_id)Le fonctionnement est le suivant :
- On insère le nœud courant
- On récupère son identifiant généré
- On appelle récursivement la fonction pour chaque enfant
Cette approche garantit que chaque nœud est correctement relié à son parent.
L’ordre d’insertion suit naturellement un parcours en profondeur de l’arbre.
V-C. Requête récursive SQL▲
Une fois les données stockées, il est nécessaire de reconstruire l’arbre pour l’exploiter.
Les bases modernes comme SQLite ou PostgreSQL permettent d’utiliser des requêtes récursives via WITH RECURSIVE.
WITH RECURSIVE tree AS (
SELECT * FROM nodes WHERE parent_id IS NULL
UNION ALL
SELECT n.* FROM nodes n
JOIN tree t ON n.parent_id = t.id
)
SELECT * FROM tree;Cette requête fonctionne en deux étapes :
- On sélectionne la racine (condition initiale)
- On joint récursivement les enfants à partir des nœuds déjà trouvés
Le résultat contient tous les nœuds de l’arbre.
Il est possible d’ajouter une colonne de profondeur pour mieux visualiser la hiérarchie :
WITH RECURSIVE tree(id, value, parent_id, depth) AS (
SELECT id, value, parent_id, 0
FROM nodes
WHERE parent_id IS NULL
UNION ALL
SELECT n.id, n.value, n.parent_id, t.depth + 1
FROM nodes n
JOIN tree t ON n.parent_id = t.id
)
SELECT * FROM tree;Les requêtes récursives permettent de reconstruire dynamiquement toute la structure de l’arbre.
Cependant, ces requêtes peuvent devenir coûteuses sur de grandes structures.
V-D. Modèles avancés▲
Le modèle parent-enfant est simple, mais il devient rapidement limité lorsque l’on souhaite effectuer des requêtes complexes ou optimiser les performances.
D’autres modèles permettent de représenter efficacement les structures arborescentes en base de données, chacun étant adapté à des cas d’usage spécifiques.
V-D-1. Materialized Path▲
Dans ce modèle, chaque nœud stocke le chemin complet depuis la racine sous forme de chaîne de caractères.
id | value | path
------------------------
1 | A | /1
2 | B | /1/2
3 | C | /1/3
4 | D | /1/2/4Cette approche permet de retrouver facilement tous les descendants d’un nœud grâce à une simple recherche sur le chemin.
Par exemple, pour trouver tous les descendants de B :
SELECT * FROM nodes WHERE path LIKE '/1/2/%';Ce modèle est simple et performant en lecture, mais les mises à jour peuvent être coûteuses en cas de déplacement de sous-arbres.
V-D-2. Nested Sets▲
Le modèle Nested Sets repose sur une numérotation des nœuds basée sur un parcours de l’arbre.
id | value | left | right
--------------------------
1 | A | 1 | 8
2 | B | 2 | 5
4 | D | 3 | 4
3 | C | 6 | 7Chaque nœud possède un intervalle qui englobe tous ses descendants.
Pour récupérer tous les descendants d’un nœud, il suffit de sélectionner les valeurs comprises entre ses bornes :
SELECT * FROM nodes
WHERE left BETWEEN parent.left AND parent.right;Ce modèle est très performant pour les lectures, mais les insertions et modifications sont coûteuses, car elles nécessitent de recalculer de nombreux indices.
V-D-3. Closure Table▲
Le modèle Closure Table consiste à stocker explicitement toutes les relations ancêtre-descendant dans une table dédiée.
CREATE TABLE closure (
ancestor INTEGER,
descendant INTEGER,
depth INTEGER
);Exemple de contenu :
ancestor | descendant | depth
------------------------------
1 | 1 | 0
1 | 2 | 1
1 | 4 | 2
2 | 2 | 0
2 | 4 | 1Ce modèle permet des requêtes extrêmement rapides pour trouver les ancêtres ou les descendants d’un nœud.
En contrepartie, il nécessite plus d’espace de stockage et une logique d’insertion plus complexe.
Le choix du modèle dépend donc du type d’application :
- Materialized Path : simple et efficace pour la lecture
- Nested Sets : très performant pour les lectures intensives
- Closure Table : flexible et puissant pour les requêtes complexes
Aucun modèle n’est universel : le choix dépend des besoins en lecture, écriture et complexité des requêtes.
Bien que les bases de données offrent des solutions puissantes pour stocker des structures arborescentes, elles ne sont pas toujours nécessaires. Dans de nombreux cas, des approches plus simples et légères permettent de représenter efficacement un arbre sans recourir à une base de données.
VI. Stocker un arbre sans base de données▲
Avant de vouloir persister un arbre dans une base de données, il est important de noter qu’il existe des solutions plus simples, souvent mieux adaptées selon le contexte.
Un arbre étant une structure naturellement hiérarchique, certains formats permettent de le représenter directement sans transformation complexe.
Le choix du mode de stockage dépend avant tout de l’usage : sauvegarde simple, échange de données ou traitement avancé.
VI-A. Sérialisation en JSON▲
Le format JSON est particulièrement adapté pour représenter un arbre, car il supporte naturellement les structures imbriquées.
class Node:
def __init__(self, value):
self.value = value
self.children = []
def to_dict(self):
return {
"value": self.value,
"children": [c.to_dict() for c in self.children]
}On peut ensuite sauvegarder l’arbre dans un fichier :
import json
with open("tree.json", "w") as f:
json.dump(root.to_dict(), f, indent=2)Exemple de contenu du fichier tree.json :
{
"value": "A",
"children": [
{
"value": "B",
"children": [
{
"value": "D",
"children": []
}
]
},
{
"value": "C",
"children": []
}
]
}Et le reconstruire :
@staticmethod
def from_dict(data):
node = Node(data["value"])
node.children = [Node.from_dict(c) for c in data["children"]]
return nodeLe JSON est simple, lisible et largement utilisé pour les échanges de données.
VI-B. Représentation en XML▲
Le XML est un autre format particulièrement adapté aux structures hiérarchiques.
Exemple de fichier XML représentant le même arbre :
<node value="A">
<node value="B">
<node value="D"/>
</node>
<node value="C"/>
</node>Cette représentation est très proche de la structure logique de l’arbre.
On peut facilement la parser en Python :
import xml.etree.ElementTree as ET
def from_xml(elem):
node = Node(elem.attrib["value"])
node.children = [from_xml(e) for e in elem]
return nodeLe XML est particulièrement intéressant lorsque l’on manipule déjà des documents structurés.
VI-C. Format texte hiérarchique▲
Une autre approche consiste à représenter l’arbre sous forme de texte avec indentation.
Exemple de fichier texte :
A
B
D
CChaque niveau d’indentation représente la profondeur dans l’arbre.
On peut parser ce format en utilisant une pile :
def parse_tree(lines):
stack = []
root = None
for line in lines:
level = len(line) - len(line.lstrip())
node = Node(line.strip())
if level == 0:
root = node
stack = [(level, node)]
else:
while stack[-1][0] >= level:
stack.pop()
stack[-1][1].children.append(node)
stack.append((level, node))
return rootCe format est très lisible pour un humain et utile pour visualiser rapidement une structure.
VI-D. Sérialisation Python (pickle)▲
Python propose également un mécanisme de sérialisation natif avec le module pickle.
import pickle
with open("tree.pkl", "wb") as f:
pickle.dump(root, f)
with open("tree.pkl", "rb") as f:
root = pickle.load(f)Le fichier tree.pkl contient une représentation binaire de l’arbre, non lisible directement par un humain.
Contrairement aux formats précédents, il ne s’agit pas d’un format texte mais d’une sérialisation interne à Python.
Le format pickle n’est pas sécurisé : il ne faut jamais charger un fichier provenant d’une source non fiable.
Il est cependant très pratique pour des usages internes ou des prototypes.
VI-E. Comparaison des approches▲
Chaque solution présente des avantages selon le contexte :
- JSON : simple, portable, idéal pour les API
- XML : structuré, adapté aux documents hiérarchiques
- Texte indenté : lisible et pédagogique
- pickle : rapide et pratique en Python
Il n’existe pas de solution universelle : le bon choix dépend du besoin.
Dans de nombreux cas, ces approches suffisent largement et évitent la complexité d’un stockage en base de données.
Maintenant que nous avons exploré différentes manières de représenter et de stocker des arbres, il est utile d’illustrer ces concepts à travers des exemples concrets.
Après avoir exploré les concepts, les parcours et les différentes méthodes de stockage, voyons maintenant comment ces structures apparaissent concrètement dans des cas d’usage réels.
VII. Exemples concrets d’arbres▲
Les structures arborescentes ne sont pas seulement théoriques : elles permettent de représenter de nombreux problèmes concrets de manière naturelle.
Voici deux exemples classiques permettant d’illustrer leur utilisation dans des contextes très différents.
VII-A. Arbre d’expression arithmétique▲
Un arbre peut être utilisé pour représenter une expression mathématique. Chaque nœud correspond à un opérateur ou une valeur :
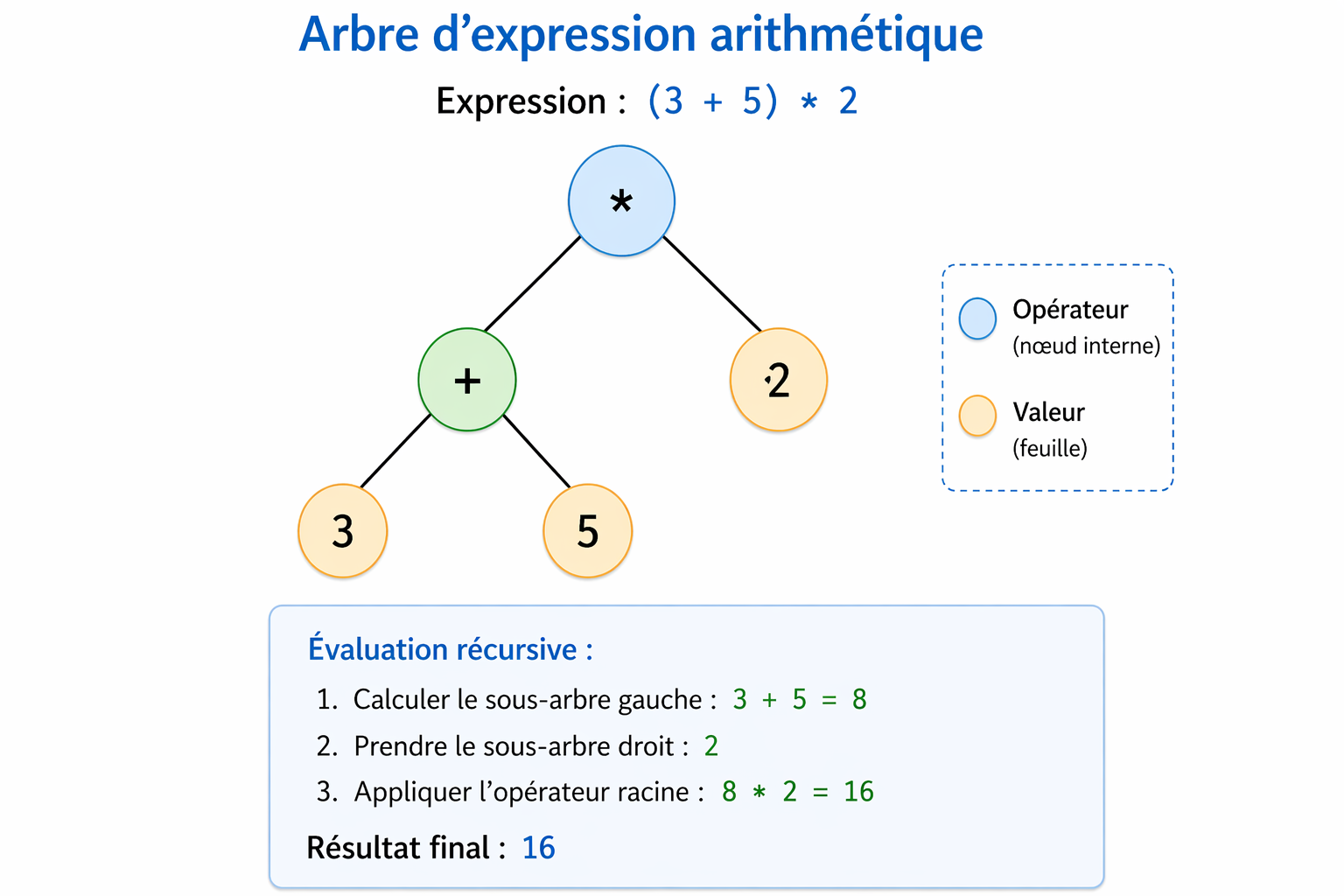
Exemple : l’expression suivante :
(3 + 5) * 2Peut être représentée sous forme d’arbre :
*
/ \
+ 2
/ \
3 5Dans cet arbre :
- Les feuilles (3, 5, 2) sont des valeurs
- Les nœuds internes (+, *) sont des opérateurs
Cette structure permet d’évaluer l’expression de manière récursive :
def evaluer(noeud):
if not noeud.children:
return int(noeud.value)
gauche = evaluer(noeud.children[0])
droite = evaluer(noeud.children[1])
if noeud.value == '+':
return gauche + droite
elif noeud.value == '*':
return gauche * droiteLe calcul suit naturellement la structure de l’arbre : on évalue d’abord les sous-expressions, puis on applique l’opérateur.
On peut également parcourir cet arbre selon différentes stratégies :
- Parcours en profondeur (DFS) : permet d’évaluer naturellement l’expression
- Parcours postfixe : correspond directement à l’ordre de calcul
Parcours postfixe :
3 5 + 2 *Ce type de parcours est utilisé par de nombreux interpréteurs pour évaluer efficacement les expressions.
Les arbres d’expression sont utilisés en compilation, en interprétation de code et dans les calculatrices.
VII-B. Arbre généalogique▲
Un arbre généalogique est un exemple très intuitif de structure arborescente :
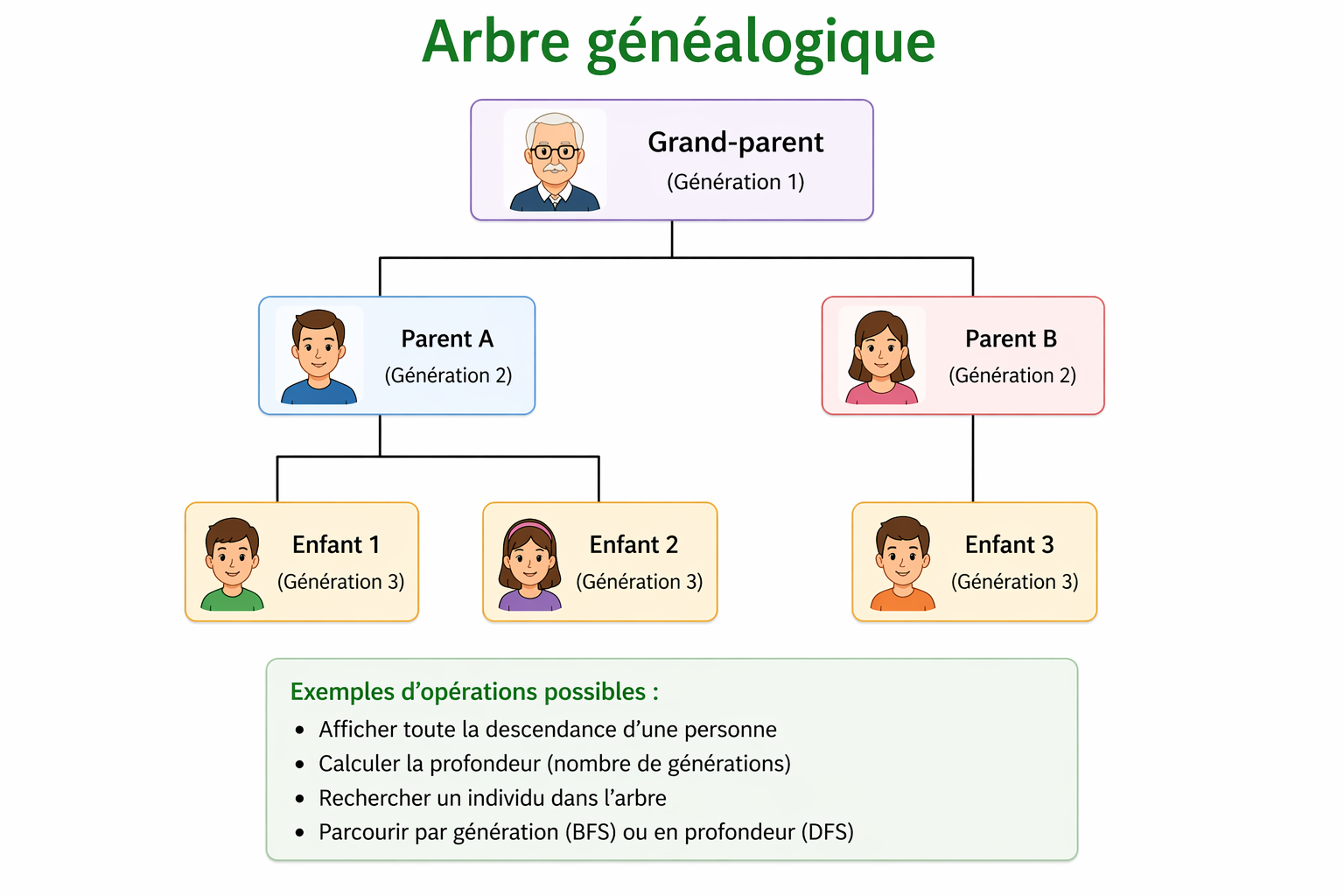
Chaque personne peut être vue comme un nœud, avec des enfants représentant la descendance.
Grand-parent
├── Parent A
│ ├── Enfant 1
│ └── Enfant 2
└── Parent B
└── Enfant 3Cette structure permet de représenter les relations familiales de manière hiérarchique.
On peut facilement effectuer des opérations comme :
- afficher toute la descendance d’une personne
- calculer la profondeur (nombre de générations)
- rechercher un individu dans l’arbre
Exemple de recherche récursive :
def rechercher(noeud, valeur):
if noeud.value == valeur:
return noeud
for enfant in noeud.children:
resultat = rechercher(enfant, valeur)
if resultat:
return resultat
return NoneCe type de structure est utilisé dans :
- les logiciels de généalogie
- les systèmes de recommandation sociale
- la modélisation des relations humaines
Les parcours d’arbre permettent également d’explorer efficacement la structure :
- Parcours en profondeur (DFS) : explorer toute une branche familiale
- Parcours en largeur (BFS) : analyser les générations niveau par niveau
Par exemple, un parcours en largeur permet d’obtenir les individus par génération :
Niveau 0 : Grand-parent
Niveau 1 : Parent A, Parent B
Niveau 2 : Enfant 1, Enfant 2, Enfant 3Les arbres permettent de représenter naturellement toute structure hiérarchique du monde réel.
VIII. Exercice guidé▲
Nous allons maintenant appliquer les concepts vus précédemment en calculant la profondeur maximale d’un arbre.
La profondeur correspond au nombre de niveaux entre la racine et la feuille la plus éloignée.
def profondeur(noeud):
if not noeud.children:
return 1
return 1 + max(profondeur(c) for c in noeud.children)Le principe est le suivant :
- Si le nœud est une feuille, sa profondeur est 1
- Sinon, on calcule la profondeur de chaque enfant
- On conserve la valeur maximale et on ajoute 1
Cette approche repose sur la récursivité et illustre parfaitement la structure d’un arbre : chaque nœud peut être considéré comme la racine d’un sous-arbre.
Exemple :
A
├── B
│ └── D
└── CLa profondeur maximale est ici de 3.
IX. Conclusion▲
Les structures arborescentes sont omniprésentes en informatique, qu’il s’agisse de systèmes de fichiers, de bases de données ou d’algorithmes complexes.
Leur compréhension permet de modéliser efficacement des relations hiérarchiques et de concevoir des solutions élégantes et performantes.
La récursivité, souvent perçue comme abstraite, devient ici un outil naturel pour parcourir et manipuler ces structures.
Nous avons également vu comment ces structures peuvent être persistées en base de données, avec différents modèles adaptés à des besoins variés.
Maîtriser les arbres et la récursivité constitue une étape clé dans la progression en programmation.
X. Remerciements▲
Je tiens à remercier tout particulièrement ... pour son aide précieuse dans la réalisation de cet article, ainsi que ... pour ses commentaires encourageants sur les premières versions de ce travail.
Sources et références
- Documentation officielle Python — Structures de données et récursivité : Python – Data Structures
- Documentation Python — Module collections (deque pour BFS) : Python – collections.deque
- SQLite — Requêtes récursives (WITH RECURSIVE) : SQLite WITH RECURSIVE
- Introduction aux arbres en algorithmique : Thomas H. Cormen et al., Introduction to Algorithms, MIT Press
- Structures de données et algorithmes en Python : Michael T. Goodrich, Roberto Tamassia, Michael H. Goldwasser, Data Structures and Algorithms in Python
- Concepts avancés de modélisation hiérarchique en base de données : Joe Celko, SQL for Smarties: Advanced SQL Programming
- Modèles de stockage des arbres en base : Materialized Path, Nested Sets, Closure Table (articles techniques et retours d’expérience développeurs)
Les exemples et illustrations de cet article ont été conçus à des fins pédagogiques.
